
DINO, a self-distillation with no labels framework, falls into the category of representation learning algorithms. It aims to learn effective representations of image data without labeled datasets, in a self-supervised fashion. This representation can be used for many tasks, such as classification, retrieval, or transfer learning. Furthermore, learned features explicitly contain the scene layout, in particular, object boundaries, directly accessible in the self-attention modules of the last block of the network.
DINO
Image-level supervision often reduces the rich visual information contained in an image to a single concept selected from a predefined set of a few thousand categories of objects. Inheriting from the success of Transformers in NLP thanks to self-supervised pretraining, DINO aims to create a pretext task that provide a richer signal than the supervised objective. DINO simplifies self-supervised training by directly predicting the output of a teacher network, built with a momentun encoder, by using a standard cross-entropy loss.
Student-Teacher Framework
DINO follows a knowledge distillation learning paradigm, where
a student network is trained to match the output of a teacher network ,
parameterized by and , respectively. Both networks share the same architecture,
which is a Vision Transformer (ViT) in this case. A MLP projection head with dimensions is attached
to align the outputs of the networks. The features used in downstream tasks come from the CLS token from the ViT backbone.
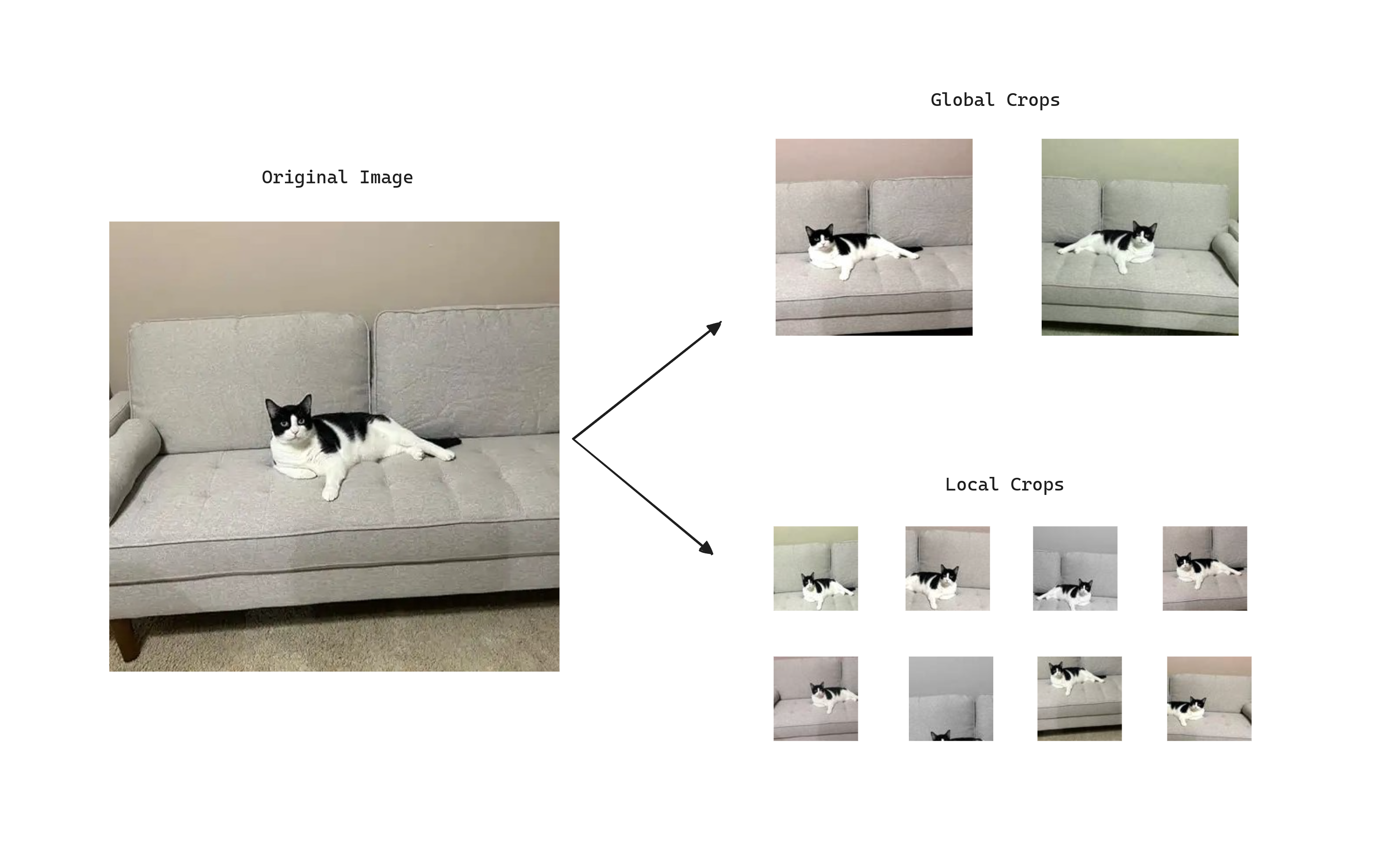
To adapt the problem to self-supervised learning, given an image DINO constructs different distorted views or crops of an image by using a multi-crop strategy. Specifically, the standard setting for multi-crop training is to use 2 global views at resolution covering an area of the image, and several local views at resolution with small areas covering of the image. Global and local crops are passed through the student network, while only the global ones are passed through the teacher. This encourages the teacher to give us generally a better representation and lead the learning process, as global views have more information compared to the local views that the student receives. At the same time, the student with local views learn to recognize fine-grained details and becomes invariant to scale changes.
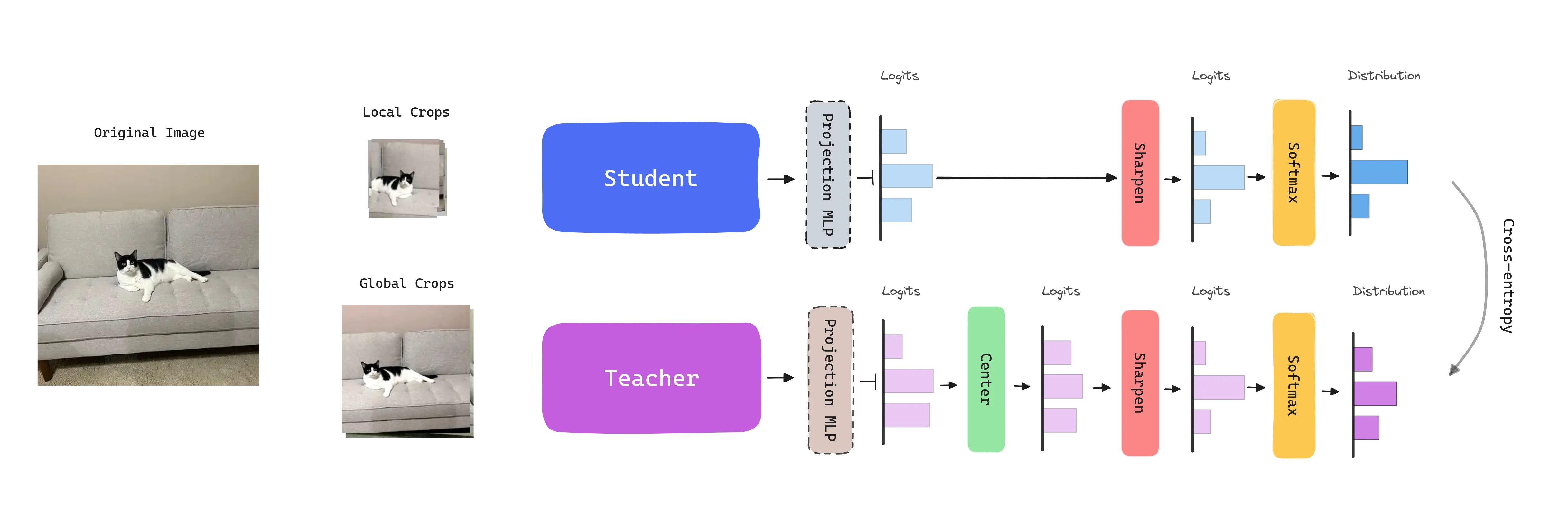
Given an input image , the crops, both networks output probability distributions over dimensions, obtained by normalizing the output of the networks with a softmax function. Given a fixed teacher network , we learn to match these distributions by minimizing the cross-entropy loss.
The student parameters are learned by minimizing the cross-entropy loss between the student and teacher outputs with stochastic gradient descent.
The teacher parameters are not given a priori and are dynamically built during training. To do so, the teacher network is freezed over an epoch and updated using an exponential moving average (EMA) on the student weights, i.e., a momentum encoder. The update rule is , with following a cosine schedule from 0.996 to 1 during training. This leads the teacher to stabilize and provide a more robust signal to the student.
The models are trained on the ImageNet dataset without labels. For evaluation 20 nearest neighbors are retrieved using the cosine similarity between the features of the images. It can be observed that reducing the size of the patches has a bigger impact on the performance than training larger models.
Avoiding Collapse: Sharp & Center
One problem DINO has is that the learnt representations can easily collapse, i.e., make the model output the same embedding for every image regardless of the input. Why not to output the same embedding for every image and technically have no error?
There are two forms of collapse: regardless of the input, the model output is uniform along all dimensions or dominated by one dimension. To avoid this, DINO introduces two strategies applied to the logits:
- Centering: Avoids the collapse induced by a dominant dimension. Depends on first-order batch statistics and can be interpreted as adding a bias term to the teacher: . The center is updated with an exponential moving average. Applied just to the teacher.
- Sharpening: The model is encouraged to output sharp predictions by using a temperature scaling factor. This factor is applied to the logits before the softmax function. Applied to the student and teacher.
Authors found that the combination of both strategies is crucial to avoid collapse and achieve good performance. If one operation is missing, the Kullback-Leiber divergence converges to zero, indicating a collapse.
Applications
Feature extraction: KNN classification
The authors demonstrate throughout the paper that DINO is capable of extracting rich self-supervised features
that perform particularly well even with a basic nearest neighbors classifier (k-NN) and without any fine-tuning.
In this section we test the features extracted from the CLS token of the ViT backbone
on the Dogs vs. Cats Kaggle dataset.
First we load the model and extract the features from the CLS token of the last block of the network.
## -- Import the necessary libraries --
# Load the DINO model
model = torch.hub.load('facebookresearch/dino:main', 'dino_vits8')
model.eval() # move the model to some device if needed
# Define the basic transformations
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
## -- Create your dataset and dataloader --
# Extract the features
features, labels, image_names = [], [], []
with torch.no_grad():
for batch, label, names in tqdm(dataloader):
output = model(batch.to(device))
features.append(output.cpu().numpy())
labels.extend(label.cpu().numpy())
image_names.extend(names)
# Group features
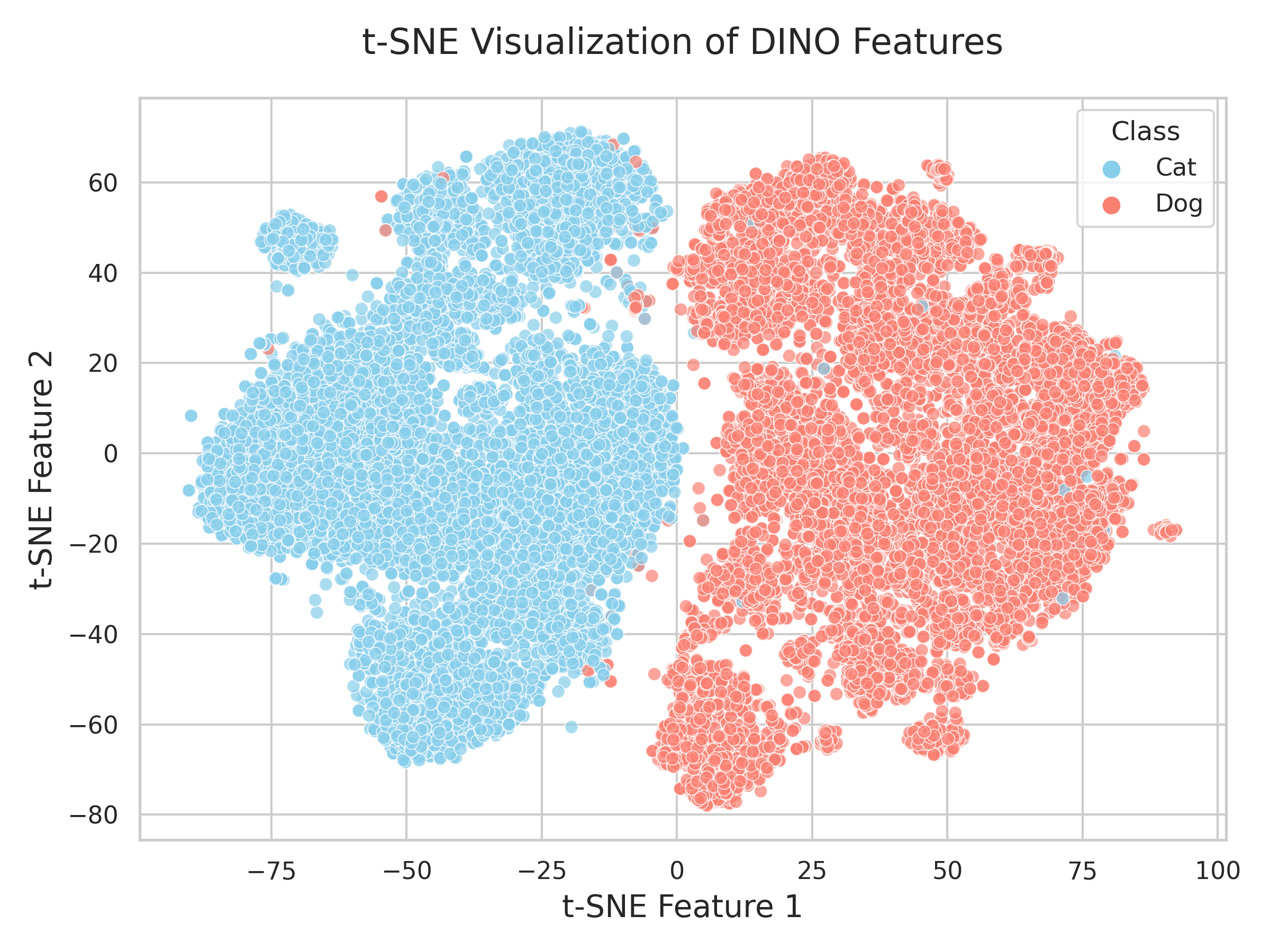
features = np.concatenate(features)Now, we can visualize the features using a t-SNE plot, by reducing the dimensionality of the features to 2D.
# Apply t-SNE
tsne = TSNE(n_components=2, random_state=42)
features_tsne = tsne.fit_transform(features)If we create a scatter plot of the features and color them by the class, we can observe that the features are well separated.
Finally, we can use a k-NN classifier to classify the images by using the features extracted.
# Split the data into training and validation sets
X_train, X_val, y_train, y_val, names_train, names_val = train_test_split(
features, labels, image_names, test_size=0.2, random_state=42, stratify=labels
)
# Create and train the KNN classifier
knn = KNeighborsClassifier(n_neighbors=20)
knn.fit(X_train, y_train)
# Make predictions on the validation set
y_pred = knn.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)The evaluation of the model shows that the model is capable of achieving a accuracy with a simple k-NN classifier.
Feature visualization: Scene layout
DINO self-attention maps contain information about the segmentation of an image. Particularly, the self-attention maps of the last block of the network contain information about the object boundaries, where different heads can attend to different semantic regions.
# Import the necessary libraries
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
# Load the model
model = torch.hub.load('facebookresearch/dino:main', 'dino_vits8')
model.eval()
# Load an image
image_path = "cat.jpg"
with open(image_path, 'rb') as f:
img = Image.open(f)
img = img.convert('RGB')
# Preprocess the image
image_size = (448, 448)
transform = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
img = transform(img)
# make the image divisible by the patch size
patch_size = 8
w = img.shape[1] - img.shape[1] % patch_size
h = img.shape[2] - img.shape[2] % patch_size
img = img[:, :w, :h].unsqueeze(0)
# forward the image
with torch.no_grad():
attentions = model.get_last_selfattention(img.to(device))
# attentions shape => (batch, num_heads, num_patches+1, num_patches+1)
# remember we have added the [CLS] token to the sequence (+1)
# we keep only the output patch attention
# We display the self-attention for [CLS] token query (index 0)
# and remove the entry for the [CLS] token query (apply 1:)
attentions = attentions[0, :, 0, 1:] # (num_heads, num_patches-1)
# reshape the attentions to the square spatial shape
nh = attentions.shape[0] # number of heads
ph = img.shape[2] // patch_size # number of patches along height
pw = img.shape[3] // patch_size # number of patches along width
attentions = attentions.reshape(nh, pw, ph)
# resize to the original image size
attentions = torch.nn.functional.interpolate(
attentions.unsqueeze(0), scale_factor=patch_size, mode="nearest"
).numpy()
# Visualize the attentions
# Create a figure with 2 rows and 3 columns (we have 6 attention heads)
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# Flatten the axes array to easily iterate over it
axes = axes.flatten()
# Plot each slice of the matrix
for i in range(6):
im = axes[i].imshow(attentions[i], cmap="hot", interpolation="nearest")
axes[i].set_title(f'Head {i+1}')
axes[i].axis('off') # Turn off axis labels
# Adjust the layout and display the plot
plt.tight_layout()
plt.show()Next there is an example of how the attention maps of the last block of the network look like.

FAQ
Why do the features used in downstream tasks come from the ViT backbone rather than the projection head?
Just like traditionally in Convolutional Neural Networks (CNNs), the features used in downstream tasks come from earlier layers of the network instead of the last layer, the backbone ViT is designed to learn general features that capture a wide range of visual concepts. On the other hand, the projection head is more task-specific, reducing the dimensionality of the features and learning a representation that is more suitable for the specific task at hand, discarding information that could be useful for other tasks. Finally, the projection head is a simple MLP, which may not preserve spatial information crucial for many downstream tasks.
Why is centering only applied to the teacher and sharpening to both the student and the teacher? Could we not apply centering to both?
My theory: Probably trial and error. My theory is that an umbalance is needed so applying the same operations not lead us again to collapse. The author responded: “I think we could also apply centering to the student as well though this is not critical to prevent collapse”.