
Research on pre-trained models indicatest that training even larger models still leads to better performances on downstream tasks. However, operating large-scale pre-trained models in on-the-edge and/or under constrained computational training or inference budgets remains challenging.
DistillBERT proposes a method to pre-train a smaller general-purpose language representation model. Through knowledge distillation during the pre-training phase authors show that is possible to reduce the size of a BERT model by 40% while rertaining 97% of its language understanding capabilities and being 60% faster. To achieve this, authors introduce a triple loss combining language modeling, distillation and cosine-distance losses.
Architecture
DistilBERT uses a student-teacher framework, where the student is trained to mimic the teacher’s predictions, also known as knowledge distillation.
The teacher is a model. The student, DistillBERT, has the same general architecture but the token-type embeddings and the pooler are removed while the number of layers is reduced by a factor of 2. Investigations show that variations in the hiddens size dimension have a smaller impact on computation effiency, so DistilBERT focus on reducing the number of layers.
An important element in the training procedure is to find the right initialization for the student to converge. Taking advantage of the common dimensionality between teacher and student networks, DistilBERT initializes the student’s weights from the teacher by taking one layer out of two.
Finally, following previous approaches like RoBERTa, DistilBERT uses a dynamic masking strategy without the next sentence prediction objective. Also, the student is distilled on very large batches leveraging gradient accumulation, up to 4K examples per batch.
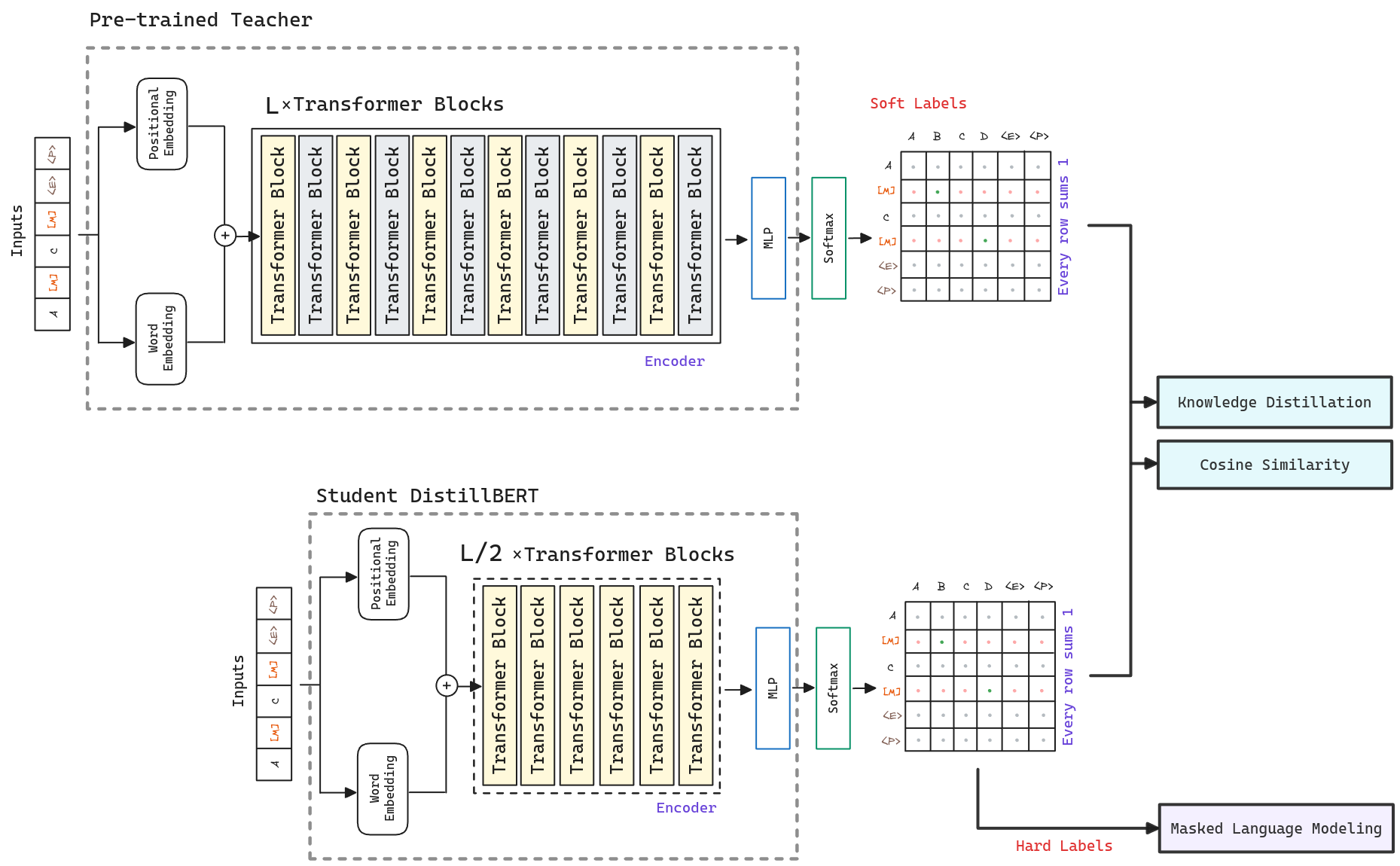
Training Losses
To leverage the inductive biases learned by larger models during pre-training, DistillBERT introduces a triple loss combining masked language modeling, distillation and cosine-distance losses. The final loss is a linear combination of the three losses.
Masked Language Modeling
As in the original BERT model, DistillBERT uses a masked language model (MLM) to train the model to predict the original vocabulary id of the masked word based only on its context.
Knowledge Distillation
Knowledge distillation is a compression technique in which a compact model- the student - is trained to reproduce the behaviour of a larger model - the teacher - or an ensemble of models.
The teacher is first trained to predict an instnace class by maximizing the estimated probability of gold labels. A standard objective thus involves minimizing the cross-entropy between the model’s predicted distribution and the one-hot empirical distribution of training labels. A model performing well on the training set will predict an output distribution with high probability on the correct class and with near-zero probabilities on other classes. But some of these near-zero probabilities are larger than others and reflect, in part, the generalization of the model and how well it will perform on the test set.
The student is then trained with a distillation loss ofver the soft target probabilities of the teacher.
Cosine-Distance
Authors found beneficial to add a cosine embedding loss which tends to align the directions of the student and teacher hidden states. This way, the student is likely not only to reproduce masked tokens correctly but also to construct embeddings that are similar to those of the teacher. Pytorch already includes a cosine embedding loss.