
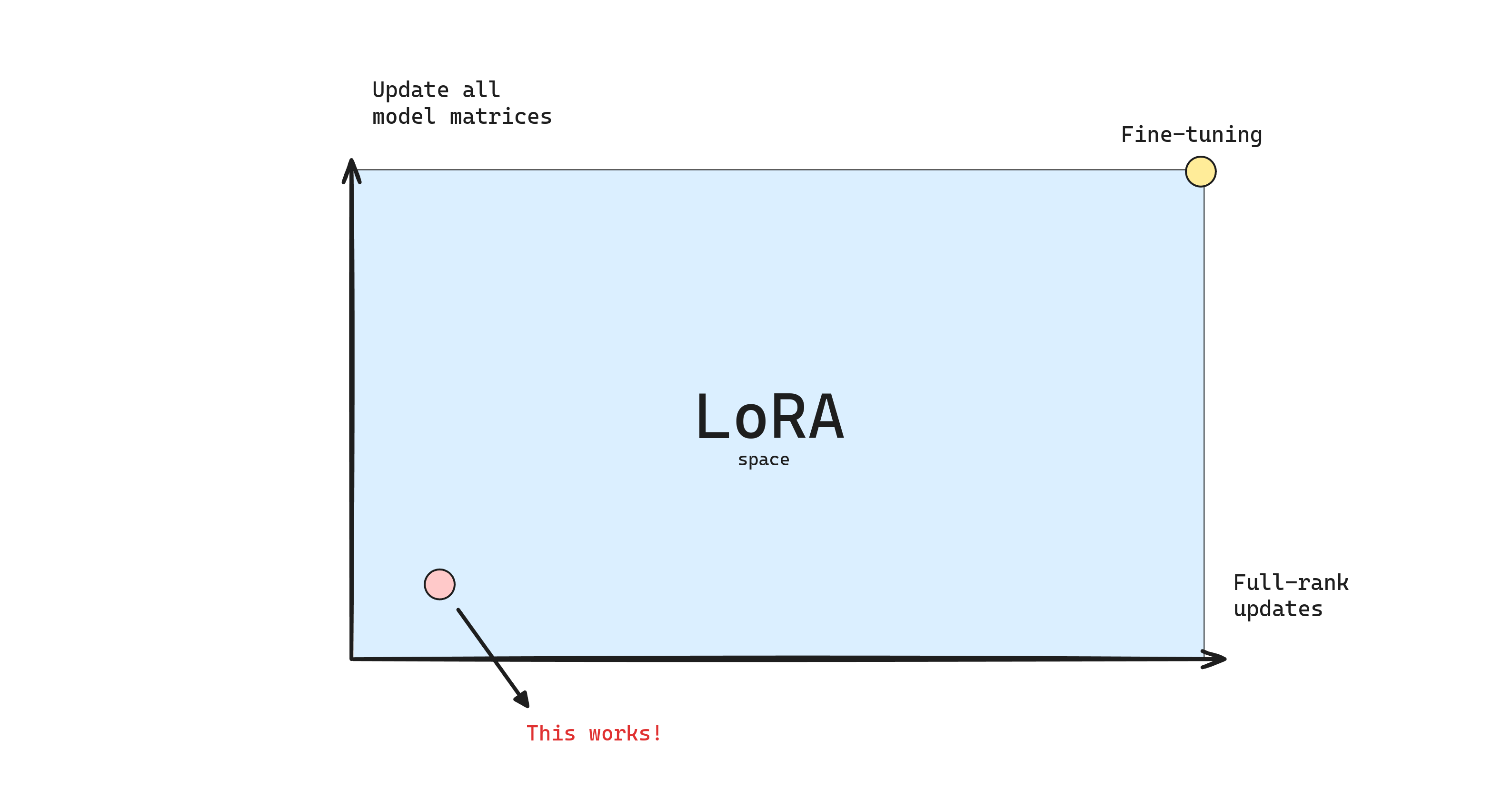
Do we need to fine-tune all the parameters? How expressive should the matrix updates be? As we want to fine-tune larger models, retraining all the parameters becomes less feasible. Low-Rank Adaptation (LoRA) proposes to freeze the pretrained model weights and inject trainable rank decomposition matrices into each layer of the architecture. LoRA reduces the trainable parameters while performing on-par than full fine-tuning.
LoRA
The principal idea apply to any dense layers in deep learning models.
Some works show that pre-trained models have a low intrinsic dimension and can still learn efficiently despite a random projection to a smaller space. LoRA hypothesizes that updating the weights also have a low intrinsic rank during adaptation.
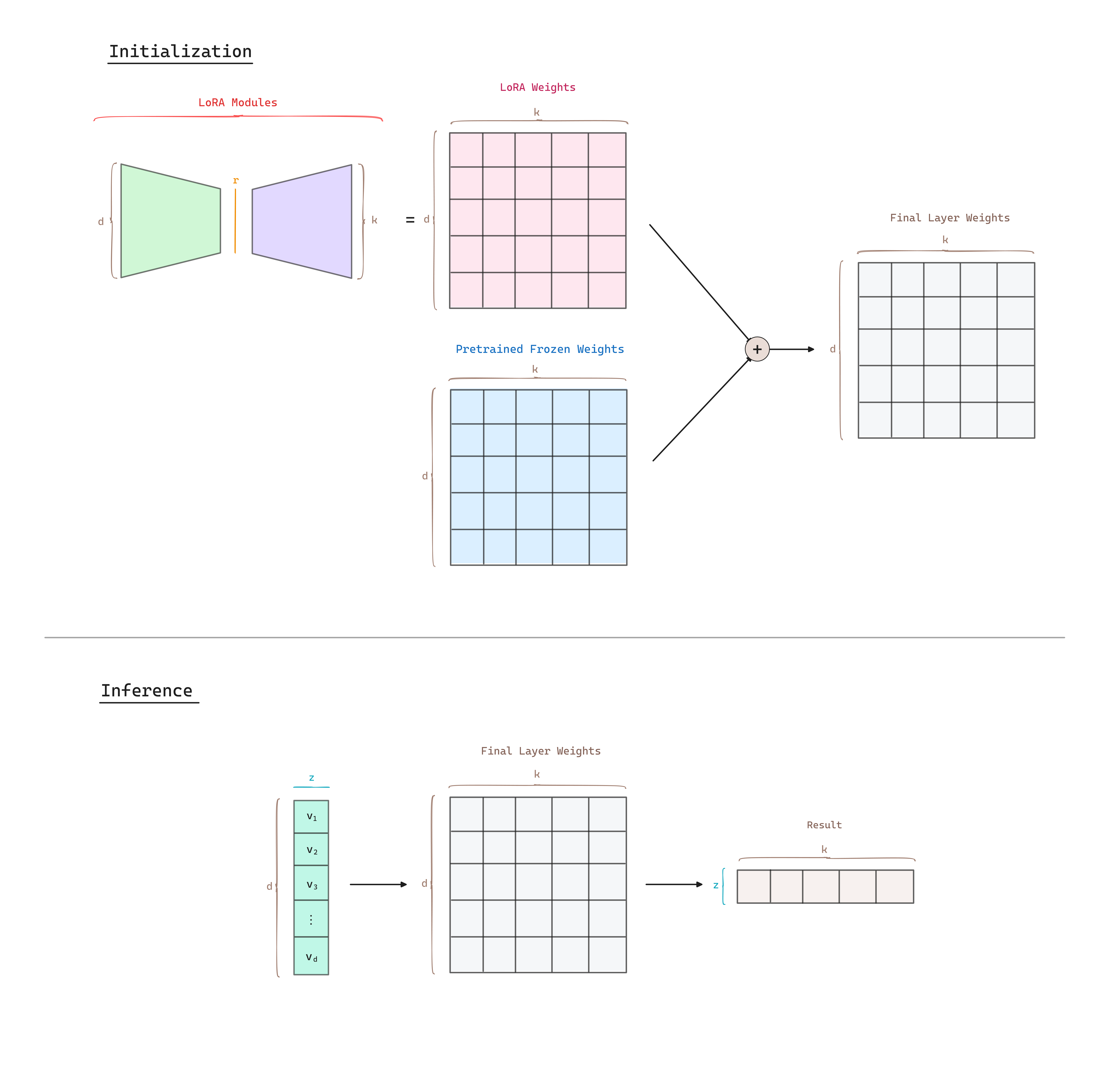
For a pre-trained weight matrix , LoRA constrain its update by representing the latter with a low-rank decomposition, i.e, , where and , seeking that the rank .
During training is frozen and does not receive gradient updates, while and contain the trainable parameters.
Next there is an example of how matrix decomposition works where the matrices have rank 1.
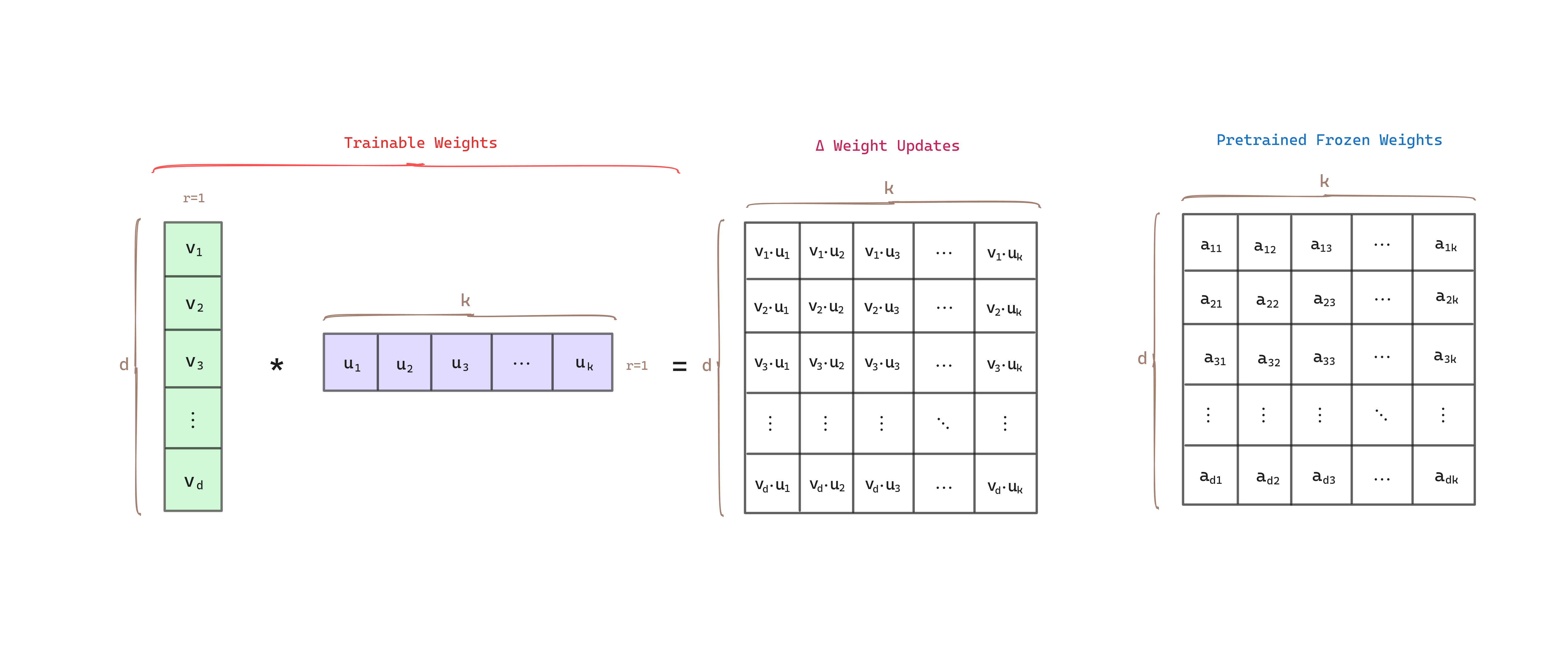
If we extend it to a general rank :
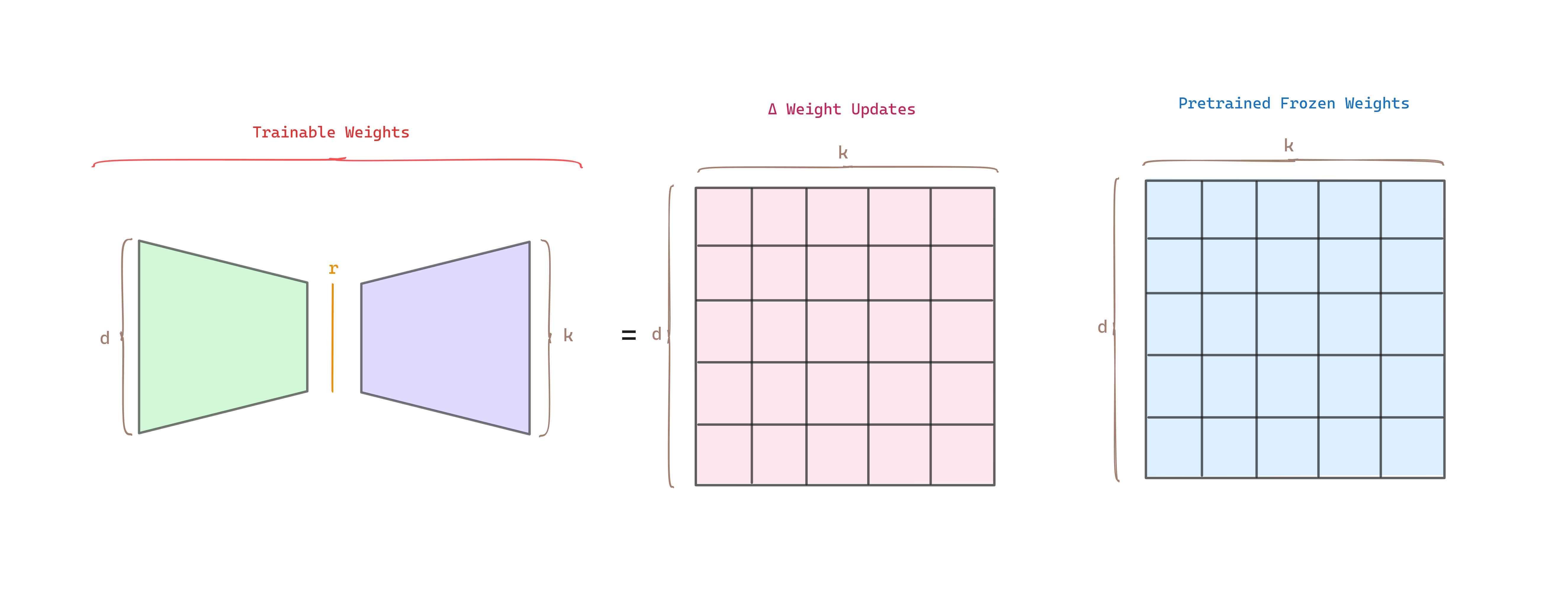
Note that, as we increase the rank and LoRA is being applied to more weight matrices, LoRA becomes similar to full fine-tuning.
Training vs. Inference
LoRA uses a random Gaussian Initialization for and zero for B, so is zero at the beginning of the training. We then scale by , where is a constant in . When optimizing with Adam, tuning is roughly the same as tuning the learning rate if we scale the initialization appropriately. Typically, is set equal to . A higher results in smaller updates, which can lead to more stable but potentially slower learning. Conversely, a lower results in larger updates, which can speed up learning but also increase the risk of instability.
At training time and are multiplied with the same input, and their respective output vectors are summed coordinate-wise.
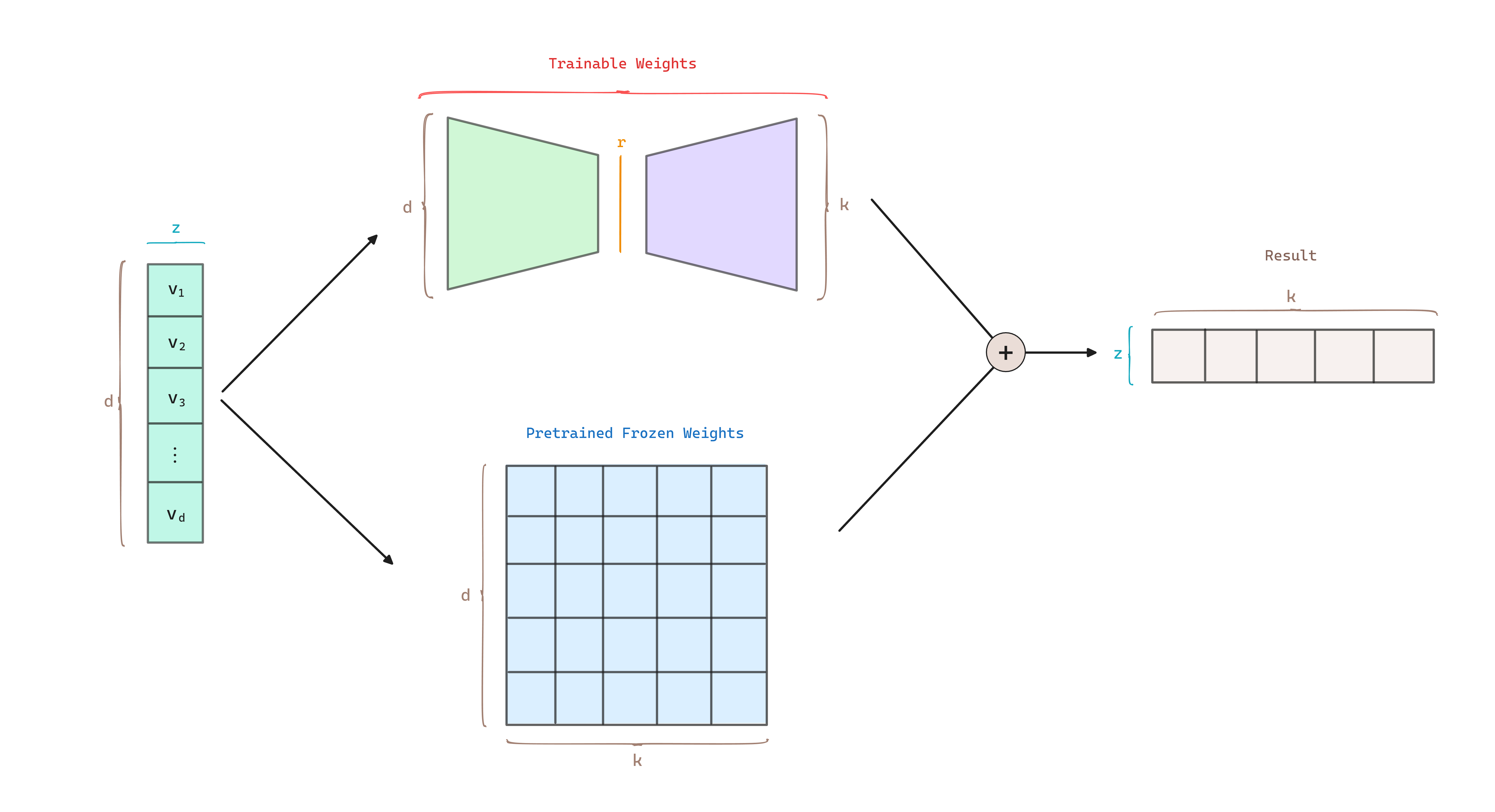
During inference, when initializing the model, we can merge the two matrices into a single matrix and apply the same input to .
Applying LoRA to Transformers
In the Transformer architecture there are four weight matrices in the self-attention module (, , , ) and two in the MLP module. Authors limit the study to only adapting the attention weights for downstream tasks and freeze the MLP modules.
The most significant benefit comes from the reduction in memory and storage usage. For a large Transformer trained with Adam, we reduce the VRAM usage by up to if as we do not need to store the optimizer states for the frozen parameters. This allows to train with significantly fewer GPUs and around a 25% speedup during the training compared to full fine-tuning, as we do not need to calculate the gradient for the vast majority of the parameters.
Benefits
- Computing Efficiency: LoRA makes training more efficient and lowers the hardware barrier to entry by up to 3 times when using adaptive optimizers since LoRA does not need to calculate the grandients or maintain the optimizer states for most parameters. Instead LoRA only optimize the injected, much smaller low-rank matrices.
- No Additional Latency: By merging the trainable matrices with the frozen weights when deployed, , introducing no inference latency.
- Task Switching: A pre-trained model can be shared and used to build many small LoRA modules for different tasks. The shared model can be freezed and efficiently switch tasks by replacing the LoRA modules. Note that both and are in , so when we need to switch to another downstream task, we can recover by subtracting and adding a different , a quick operation with very little memory overhead.
- Storing Efficiency: One of the drawbacks for full fine-tuning is that for each downstream task, we learn a different set of parameters. If the model is large, storing and deploying many independent instances of fine-tuned models can be challenging, if at all feasible. For example, for a base model of 350GB, storing 100 full fine-tuned models would require 35TB of storage. With a sufficient small LoRA the checkpoint size is reduced roughly , ending up with 350GB + 35MB * 100Models 354GB.
Tips
- Which weight matrices in Transformer should we apply LoRA to?
- Authors experiment that it is preferable to adapt more weight matrices than adapting a single type of weights with larger rank.
- How to choose the rank ?
- LoRA performs competitively with a very small , suggesting the update matrix could have a very small intrinsic rank.
- What to do if LoRA underperforms?
- If LoRA underperforms, adapt more parameters and/or increase the rank.