I know, I know, you are tired of hearing about Precision, Recall and F1 Score, or if not probably you can find a lot of information about them on the internet better than this post. But this blogs serves me as a second brain, so if at any time I lose my mind, I can quickly recover my ideas.
That said, let’s start with the post.
Introduction
The Precision, Recall and F1 Score are metrics used to evaluate the performance of a classification model, particularly for binary classification problems. This is not limited to machine learning, but it is also used in other fields such as information retrieval, where precision and recall are used to measure the effectiveness of a search engine as having two classes: relevant and irrelevant.
If we expand our mind we can apply these metrics to another problems like detection ones, where we can consider the positive class as the class being detected (for example if reached a certain Intersection over Union threshold), and the negative class if the class or object is not detected.
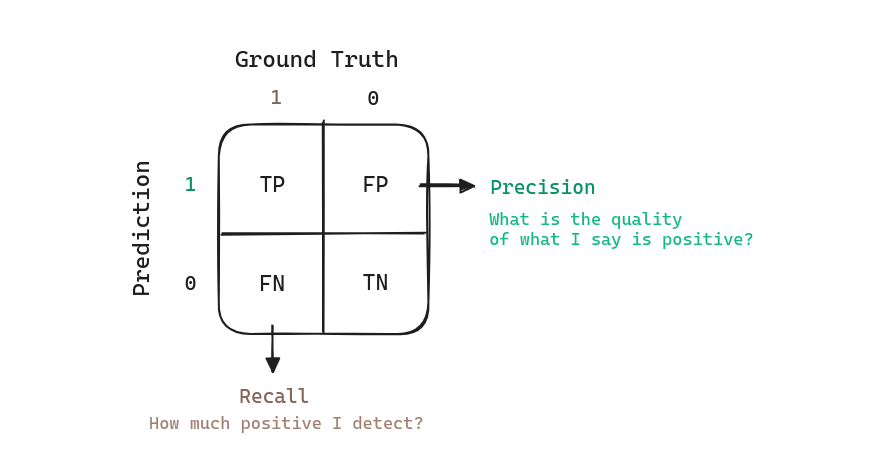
Precision
The precision is the ratio of the True Positives (TP) over the sum of the True Positives and False Positives (FP): . The precision can be interpreted as the quality of my predictions. Of the samples that I have classified as positive, how many are actually positive.
How the precision changes when we change the confidence threshold with which we assign the class?
- If we raise the confidence threshold with which we assign the class, few samples will be positively assigned, only those that the system has high confidence in. This will decrease the number of false positives and we will be able to state that the samples classified as positive are very likely to be positive. We will have a high precision, we can be sure that the samples classified as positive are very likely to be positive, but we will be missing a lot of samples of the positive class.
- If we lower the confidence threshold with which we assign the class, many samples will be positively assigned, even those that the system has low confidence in. This will increase the number of false positives and we will not be able to state that the samples classified as positive are very likely to be positive. We will have a low precision, we cannot be sure that the samples classified as positive are very likely to be positive.
Recall
The recall is the ratio of the True Positives (TP) over the sum of the True Positives and False Negatives (FN): . The recall can be interpreted as the completeness or quantity of my predictions. How many samples of the positive class I have detected.
How the recall changes when we change the confidence threshold with which we assign the class?
- If we raise the confidence threshold with which we assign the class, few samples will be positively assigned, only those that the system has high confidence in. This will decrease the number of true positives and increase the number of false negatives, as is very likely that we will be stating that a sample is negative when it is actually positive. We will have a low recall, we probably will be missing a lot of samples of the positive class, being unable to detect them.
- If we lower the confidence threshold with which we assign the class, many samples will be positively assigned, even those that the system has low confidence in. This will increase the number of true positives and decrease the number of false negatives, all will be classified as positive. We will have a high recall, we will be able to detect almost all the samples of the positive class, but we will have a lot of false positives.
F1 Score
The F1 Score is the harmonic mean of the precision and recall: . The F1 Score can be interpreted as the harmonic mean of the precision and recall, it is a metric that combines precision and recall.
Why to use F1 Score instead of the precision or recall? Usually when we are training a model we want to maximize the precision and recall at the same time, but this is not possible. As we have seen, when we increase the precision we decrease the recall, and vice versa. So we need a metric that combines both metrics, and the F1 Score is a good candidate. On the validation phase having and unified metric is useful to compare different models, and to choose the best one.
TL;DR
- Precision: The quality of my predictions. Of the samples that I have classified as positive, how many are actually positive.
- Recall: The quantity of my predictions. How many samples of the positive class I have detected.
- F1 Score: The harmonic mean of the precision and recall. It is a metric that combines precision and recall.
I will want to maximize the precision and recall at the same time, but this is not possible, or at least not easy. So I will use the F1 Score to compare different models and to choose the best one.
I will want to state that the samples that are positive really are positive (precision), and that I have detected all the samples of the positive class (recall).