BERT - Bidirectional Encoder Representations from Transformers

Abstract
Left-to-right architectures may be sub-optimal for sentence-level tasks such as sentence classification, and very harmful for token-level tasks such as question answering or named entity recognition. There are tasks where incorporating context from left and right of a token is crucial .
BERT, which stands for Bidirectional Encoder Representations from Transformers, aims to alleviate the problem of unidirectionality by using a masked language model (MLM) pre-training objective, inspired by the Cloze task. In addition, authors also use a next sentence prediction task that jointly pretrains text-pair representations.
There are two steps in BERT framework: pre-training and fine-tuning . BERT aims to first understand the language, and then use that understanding to perform a task. This way, the model can be fine-tuned to perform a wide variety of tasks with minimal additional training.
Architecture
BERT’s model architecture is a multi-layer bidirectional Transformer Encoder , almost identical to the original Transformer implementation.
BERT denotes the number of the Transformer encoder blocks as , the hidden size as , and the number of self-attention heads as . BERT initial model designs are the following:
| Model Name | (Transformer blocks) | (Hidden size) | (Self-Attention heads) |
|---|---|---|---|
| 12 | 768 | 12 | |
| 24 | 1024 | 16 |
Pre-training
The objective of pre-training is to learn a general-purpose language representation that can be used for downstream tasks. BERT focuses on two unsupervised tasks:
- Learning from the surrounding context , through a masked language model.
- Learning from the relationship between two sentences , through a next sentence prediction task (helpful for some downstream tasks such as question answering).
Both tasks are trained at the same time, summing their losses . For the pre-training corpus, BERT uses the BooksCorpus (800M words) and English Wikipedia (2,500M words). Note that it is critical to use a document-level corpus rather than a shuffled sentence-level corpus, so long contiguous sequences can be used.
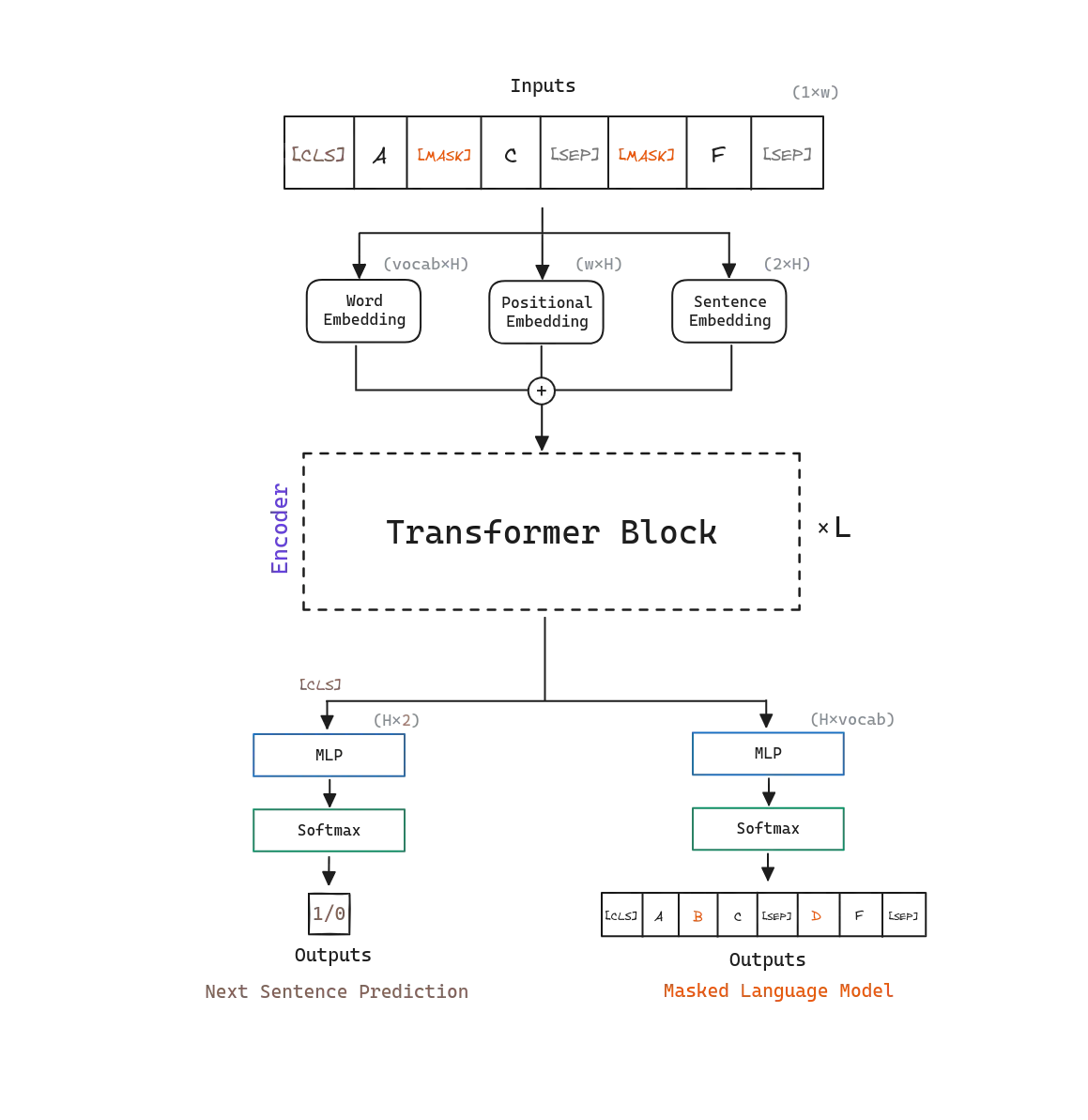
Masked Language Model
The bidirectional context understanding can enable to capture intricate dependencies and relationships among words, resulting in more robust and contextually rich representations.
Previous methods suffered from the unidirectionality constraint: a word can only attend to previous words in the self-attention layers. In order to train deep bidirectional representations, BERT simply masks some percentage of the input tokens at random , and then predicts those masked tokens. This is different from traditional language modeling, where the model is trained to predict the next word in a sequence where only the previous words are visible. BERT authors refer to this procedure as a masked language model (MLM).
The procedure is as follows:
- Tokenize the input sequence.
- Replace 15% tokens with:
- 80% of the time:
[MASK]token. - 10% of the time: a random token.
- 10% of the time: the original token.
- 80% of the time:
- Feed the sequence to the model.
- Only for the replaced tokens, compute cross entropy loss between the output and the original sequence.
Although MLM allows BERT to obtain a bidirectional pre-trained model, a downside is that it creates a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. That’s why BERT sometimes replaces the masked tokens with the original and random tokens.
Next Sentence Prediction
Some downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between sentences.
In order to train a model that understands sentence relationships, BERT authors pre-train the model with a simple task called next sentence prediction . For next sentence prediction two sentences are chosen at random, and the model is trained to predict whether the second sentence is the actual next sentence in the original document. The model is trained with 50% of the time the second sentence is the actual next sentence , and 50% of the time it is a random sentence from the corpus.
BERT adds a special token called [SEP] between the two sentences and a [CLS] token at the beginning of the first sentence. The final hidden state of this [CLS] token is used for next sentence prediction . In addition, BERT adds learned embeddings to every token indicating whether it belongs to the first or second sentence .
Fine-tuning
Swapping out the appropriate inputs and outputs, BERT can be used for a wide variety of downstream tasks, whether they involve single text or text pairs . To do so, BERT fine-tunes all the parameters end-to-end. Compared to pre-training, fine-tuning is relatively inexpensive.
At the output, the token representations are fed into an output layer for token-level tasks such as named entity recognition, and the [CLS] representation is fed into an output layer for classification tasks such as entailment or sentiment analysis.