Depthwise Separable Convolutions

Commonly used in networks as MobileNet, the depthwise separable convolutions consists of two steps: depthwise convolutions and convolutions.
Standard convolution
Before describing the depthwise separable convolution, it is worth revisiting the typical convolution. For a concrete example, let’s say an input layer of size (height width channels), and 128 filters of size , after applying one filter, the output layer is of size (only 1 channel), and grouped up with the 128 filters, .
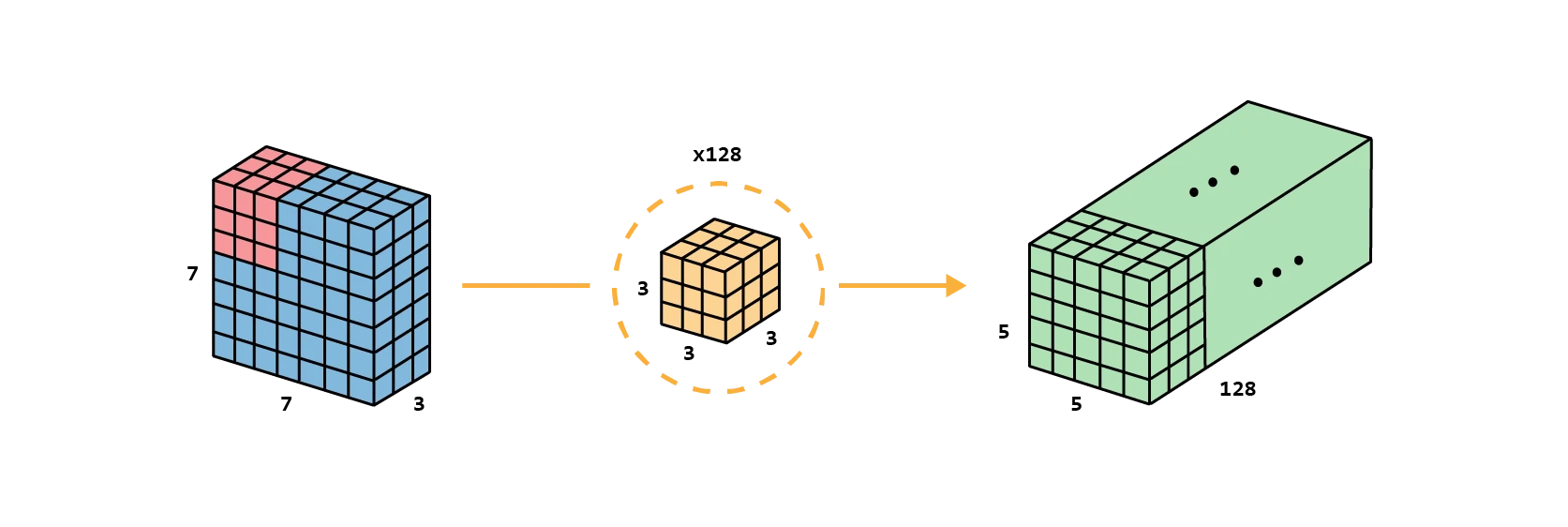
Illustrated through code:
# Input volume with depth 3 and outputs 128 kernels
# Uses 3×3 convolutional kernel
conv_layer = nn.Conv2d(in_channels=3, out_channels=128, kernel_size=3)Depthwise Separable Convolutions
Let’s see how we can achieve the same transformation as the standard convolution with less computation .
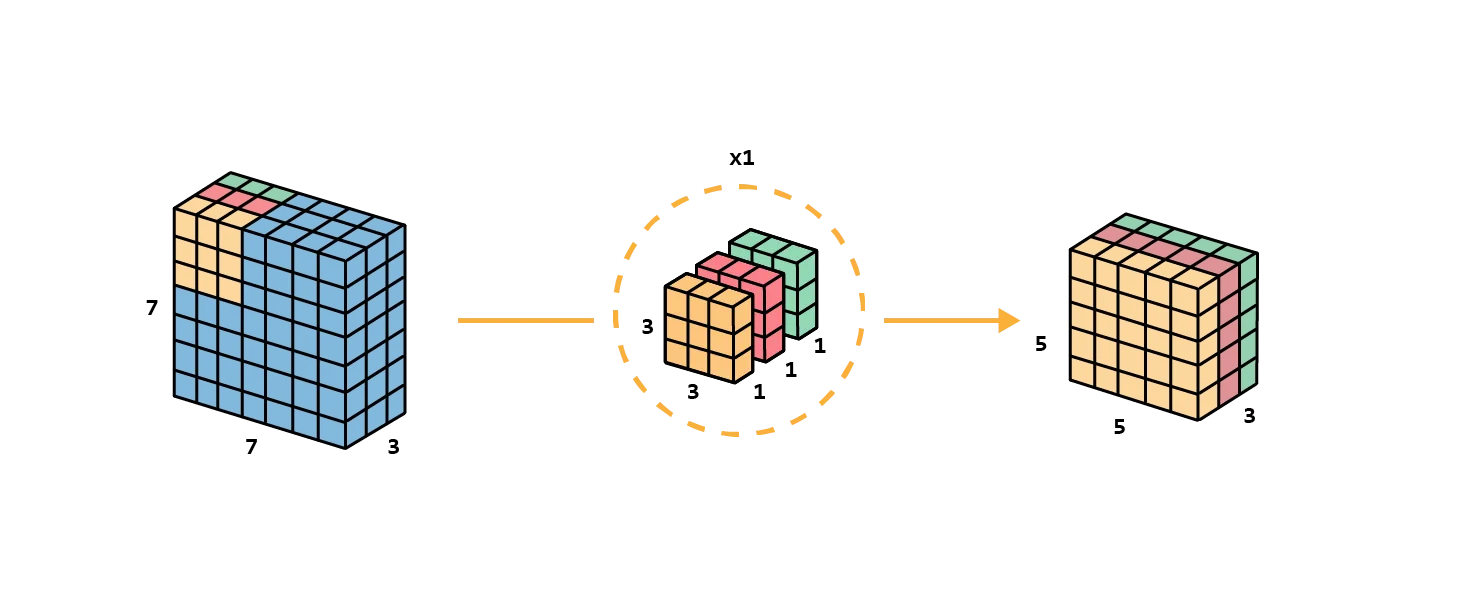
We first apply depthwise convolution to the input layer. Instead of using a single filter of size , we will use 3 kernels separately . Each filter has a size of , each kernel convolves with 1 channel of the input layer ( 1 channel only, not all channels! ). Each such convolution, in the example, will provide a map of size , and we will stack them to create a image. We shrunk the spatial dimension, but the depth is still the same as before.
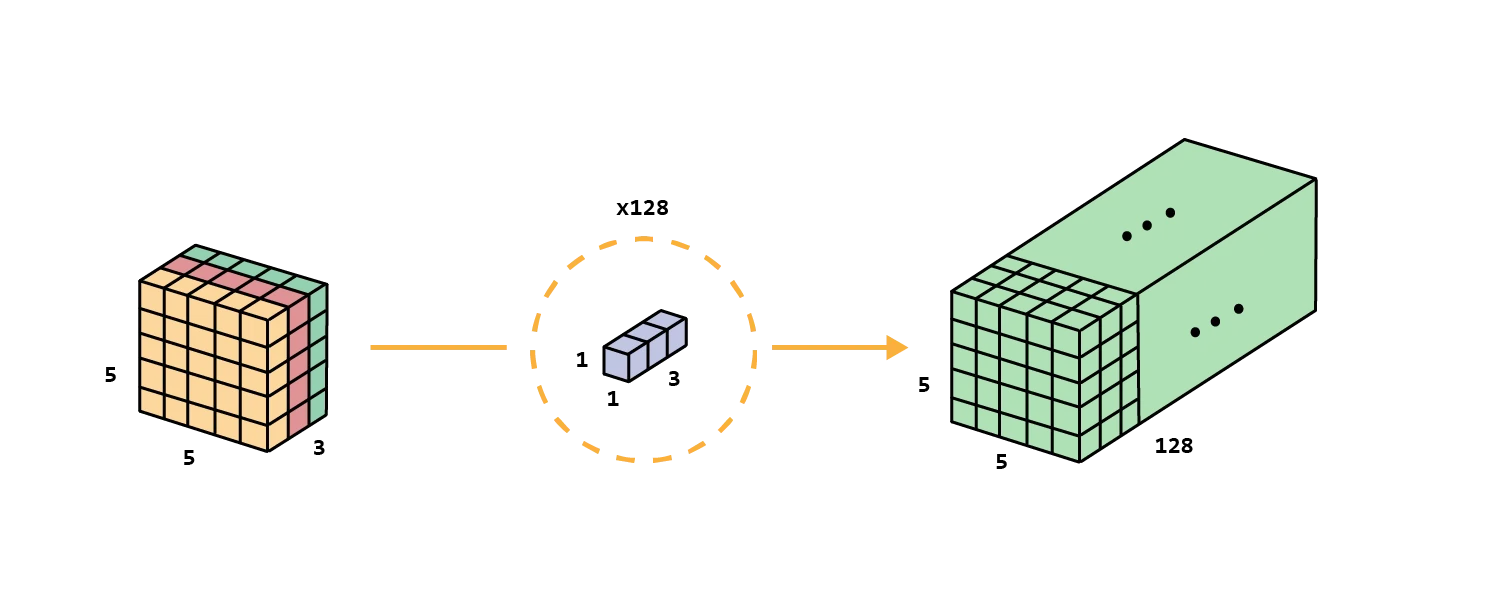
Then, it’s time for the second step, extend the depth by applying convolutions , as many as the depth we want to achieve, as for the example 128 filters.
With these steps, we also (as in the standard convolution) transform the input layer into the output layer as for the standard convolution. The overall process of the depthwise separable convolution would be:
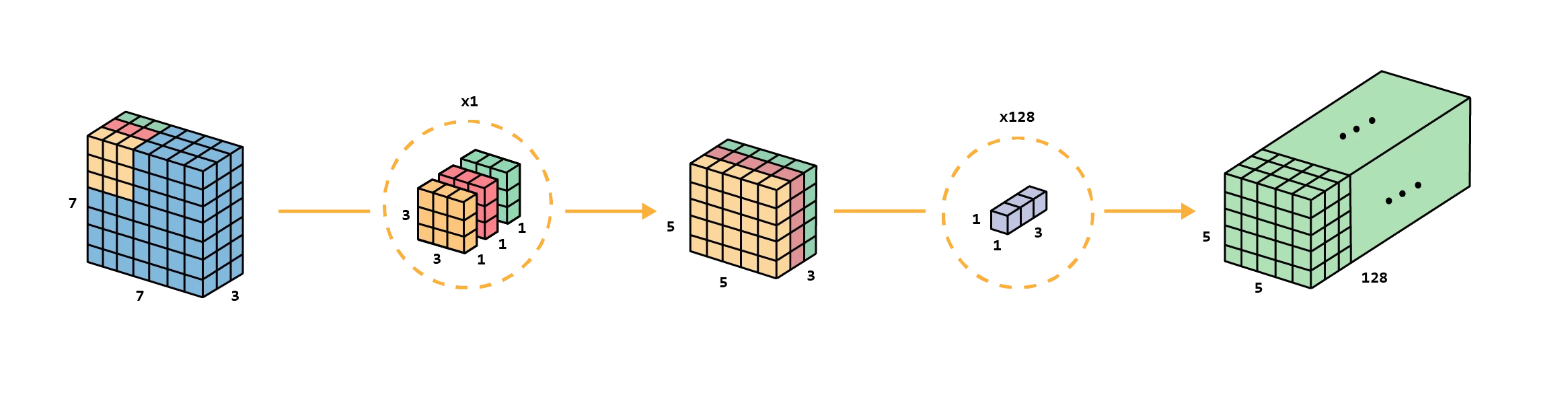
Which would be defined as:
# Define depthwise separable convolutional layer
# Note how we use the groups parameter: At groups equals to in_channels,
# each input channel is convolved with its own set of filters
depthwise_conv_layer = nn.Conv2d(
in_channels=3, out_channels=3, kernel_size=3, groups=3
)
pointwise_conv_layer = nn.Conv2d(
in_channels=3, out_channels=128, kernel_size=1
)The advantage of doing depthwise separable convolutions is the efficiency . One needs much less operations for depthwise separable convolutions compared to standard convolutions.
Meanwhile for the standard convolutions we need to move 128 filters with dimensionality around the input times, i.e., 86400 multiplications, the depthwise separable convolution uses 3 kernels that moves times, and after that, 128 filters of dimensionality that moves times over the previous output, i.e., 9600 multiplications, only about the 12% of the cost of the standard convolution (for this example convolution configuration).