
GPT explores a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training, assuming access to a large corpus of unlabeled text, and datasets with manually annotated training examples for supervised fine-tuning. To do so, GPT employ a two-stage training procedure:
- First, it uses a language modeling objetive on the unlabeled data to learn the initial parameters of a neural network model.
- Subsequently, it adapts the model parameters to a target task using the corresponding supervised objective.
Furthermore, this approach showcases zero-shot behaviors of the pre-trained model on different settings, demonstrating that GPT acquires useful linguistic knowledge for downstream tasks during the unsupervised pre-training phase.
Architecture
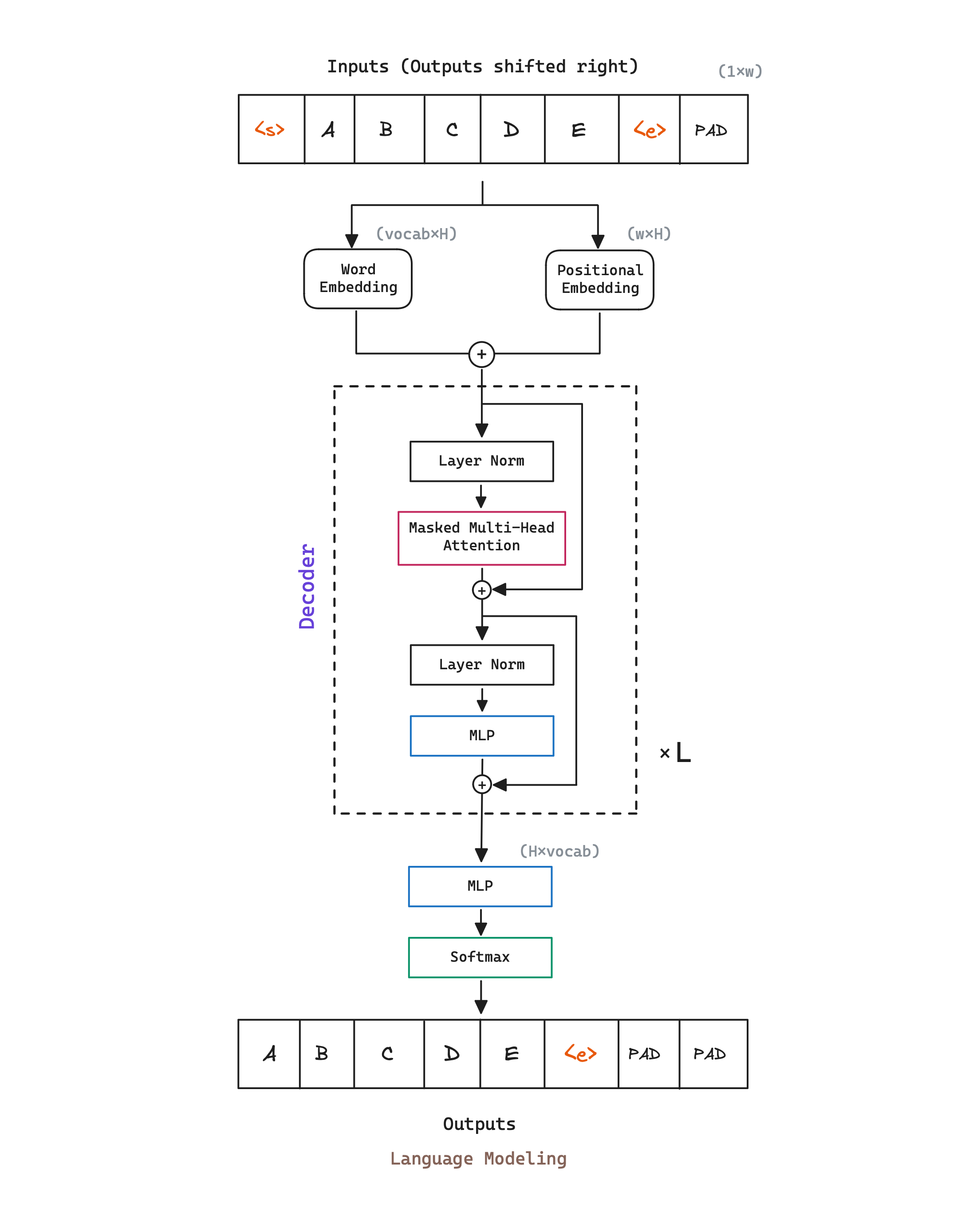
GPT model architecture is a multi-layer causal Transformer Decoder, almost identifical to the original Transformer implementation. If you want more details about the Transformer architecture, you can check out my Transformer blog post.
We can denote the number of the Transformer decoder blocks as , the hidden size as , and the number of self-attention heads as . GPT initial model design is the following:
| Model Name | (Transformer blocks) | (Hidden size) | (Self-Attention heads) |
|---|---|---|---|
| 12 | 768 | 12 |
Additionally, GPT uses a bytepair encoding (BPE) vocabulary with merges. Authors use the ftfy library to clean the raw text in BookCorpus dataset, standardize some punctuation and whitespace, and use the spaCy tokenizer.
Pre-training
Learn effectively from raw text is crucial to alleviating the dependence on supervised learning. Even in cases were considerable supervision is available, learning good representations in an unsupervised fashion can provide a significant performance boost.
Given a unsupervised corpus of tokens,
GPT uses a standard language modeling objective to maximize the likelihood.
This task consists of predicting a token given its previous context.
As in the Transformer, this task can be performed in an unsupervised way
by taking sequences of tokens and adding a padding on the initial input,
typically a special token, <s> for our illustration.
Fine-tuning
After training the model, GPT adapts the parameters to a supervised target task.
Given a labeled dataset , where each instance consists of a sequence of input tokens,
, along with a label . The input are passed through the pre-trained
model to obtain the final transformer block’s activation (<e>),
which is then fed into an added linear output layers with parameters to predict .
Authors additionally found that including
language modeling as an auxiliary objective
to the fine-tuning helped improving generalization and accelerating convergence.
GPT setup does not require fine-tuning target tasks to be in the same domain as the unlabeled corpus used during pre-training. During transfer, GPT utilizes task-specific input adaptations, always processing structured text input as a single contiguous sequence of tokens. Taking that into account, minimal changes to the architecture of the pre-trained model are done.
Task-specific input transformations
For some tasks, like text classification, we can directly fine-tune GPT as described above. For other tasks, it is possible to convert structured inputs into an ordered sequence that the pre-rtained model can process.These input transformations allow GPT to avoid making extensive changes to the architecture across tasks.
Textual entailment. For entailment taks, simply concatenate the premise and hypothesis token sequences, with a delimiter token ($) in between. Process and obtain final transformer block’s activation.
Similarity. For similarity taks there is no inherent ordering of the two sentences being compared. To reflect this, authors modify the input sequence to obtain both possible sentence orderings and process each independently to produce two sequence representations which are added element-wise before being fed into the linear output layer.
Question Answering and Commonsense Reasoning. For these tasks, we are given a context document , a question , and a set of possible answers . Authors concatenate the document context and question with each possible answer, adding a delimiter token in between to get . Each of these sequences are processed independently to obtain scores that are later normalized via a softmax layer to produce an output distribution over possible answers.
Glossary
- : Number of Transformer decoder blocks.
- : Size of the embeddings. An embedding is a learnable representation of the words of the vocabulary.
- : Number of self-attention heads.
- w: Input sequence length.